友情链接:

(原标题:Deepseek爆红背后的3个关键词)欧洲杯体育
本来以为年夜可以休息一下,不再更新,不外早上通盘来发现隔夜英伟达的股票大跌了16%,同期Deepseek又发布了一个新的多模态模子——Janus-Pro-7B。
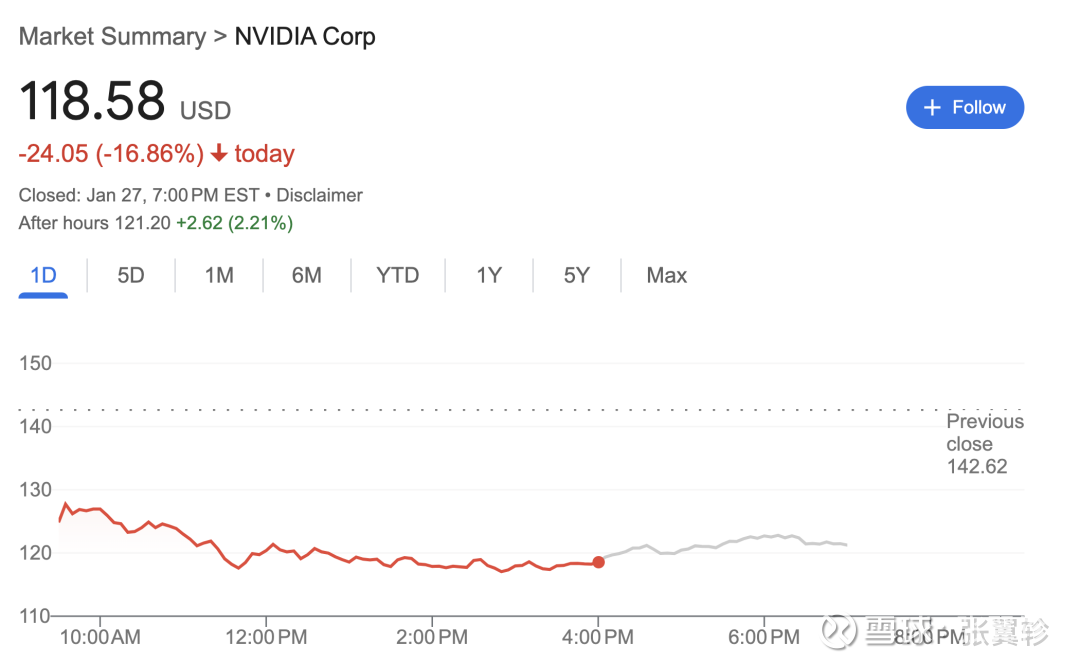
天然这两件事对宏大A股投资者的联系不是那么大,尤其咱们还要休市整整一周,但接洽到总计半导体行业对 A股的成长股照旧有着相配庞杂的映射,再加上这亦然近期最热点的话题。
本着追踪A股总计东说念主工智能、机器东说念主、半导体行业的发展角度,我以为照旧有必要写一篇聊一聊我眼中此次Deepseek爆红的四个关键词,不是时刻层面的考量,更多是一些道理的不雅察。
API 与编程
第一个点是API和编程。
其确凿Deepseek发布 R1 模子的同日,Kimi 也发布了深度推理的有关模子,关联词你会发现如今东说念主东说念主提的都是 Deepseek,Kimi 这件事险些被公共渐忘了。
为什么会出现这么的情况?咋看有点乖癖,毕竟从 Kimi 发布的数据来看,其实模子的质地不差。
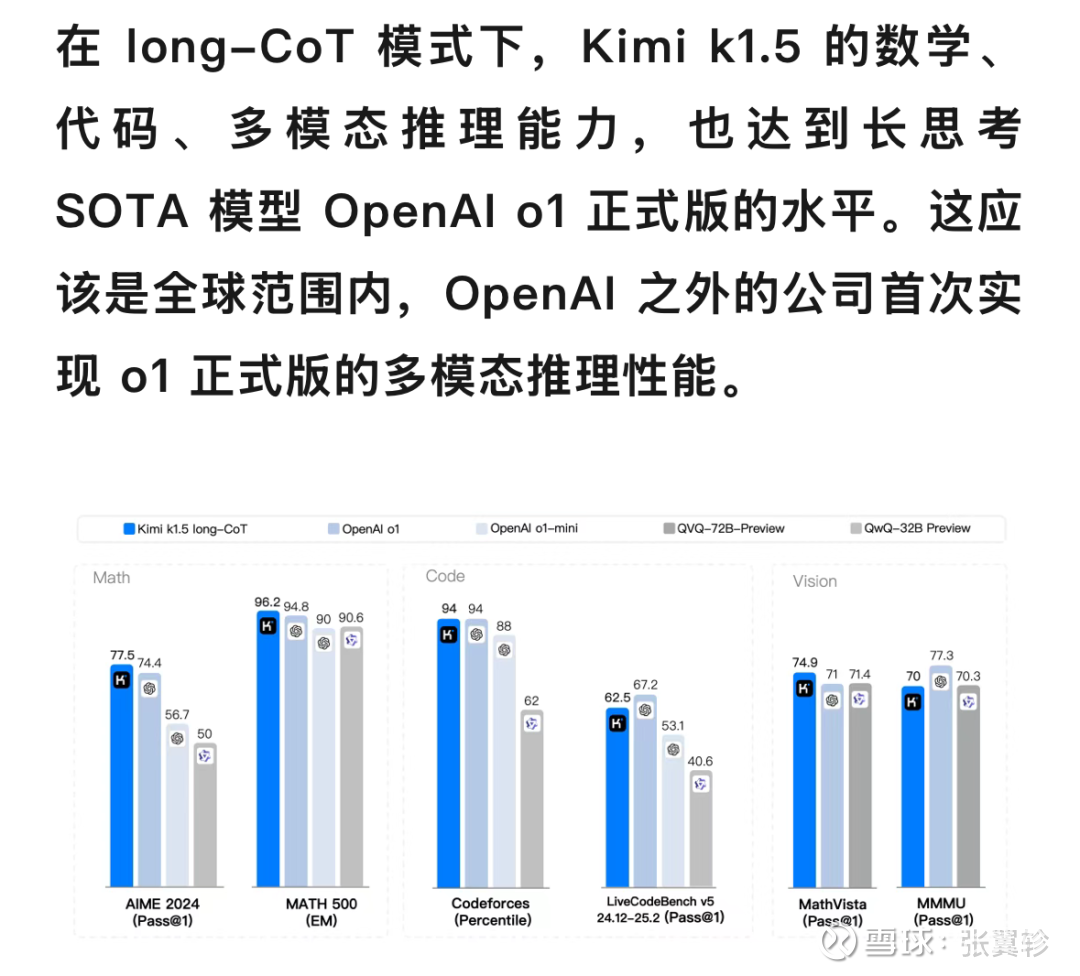
但其后再仔细一念念,尤其是查了一下 Kimi 的开发者平台,我以为一个很可能的原因即是 Kimi 照旧预览版,并莫得老练的 API 可用。
这里咱们转头一下时刻线,Deepseek其确凿 2024 年 11 月 20 日就发布了 R1 Lite 模子,那时就强调在相配多的数据比赛中依然赶超了 OpenAI 的 O1 模子。
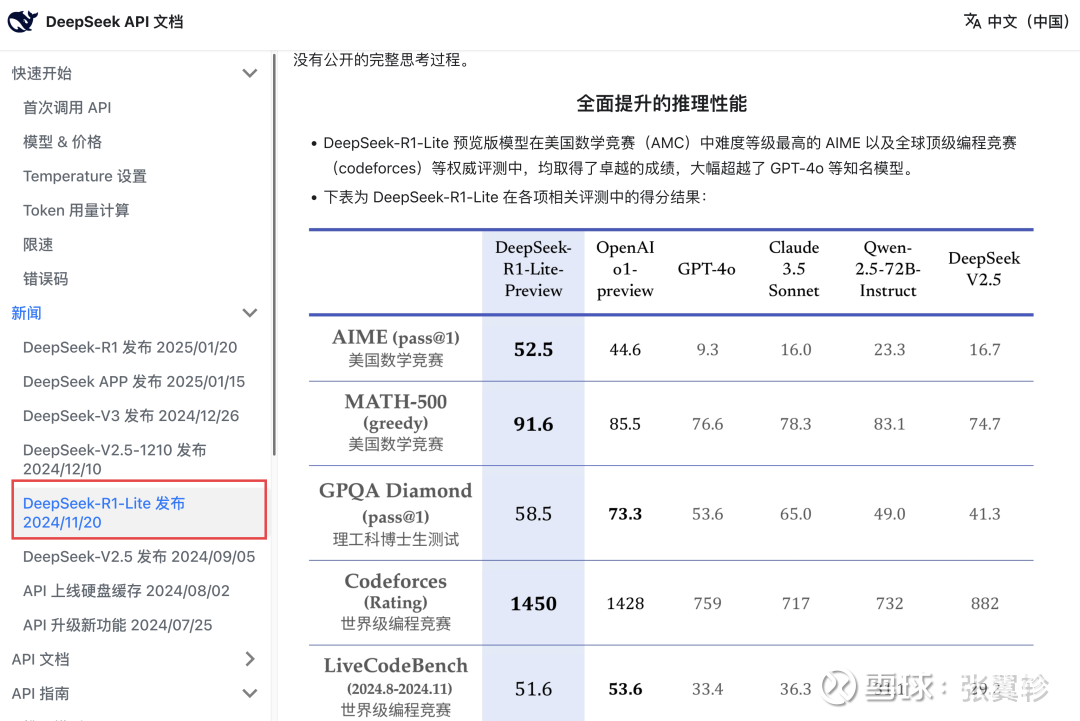
关联词那时阿谁模子只可在官方网页上使用,是以并莫得破圈。
关联词 1 月 20 日,此次 R1 模子发布之后是同步上线了 API,这意味着可以通过各样要害去调用,我以为其实是Deepseek此次大幅走红相配庞杂的少许。
你看这一波在赞叹Deepseek的用户,最多的一批是来自于 X (原Twitter) 上的要害员,他们正本的代码最好推行是继承 OpenAI 的 o1 模子进行总计要害开发的架构盘算推算,然后再用 Claude Sonnet 3.5进行编码。这么的操作天然流露很可以,关联词 o1 模子的本钱确凿是太高了。
在这么的一个前提下,追随 Deepseek R1 发布了 API,这意味着可以将正本的责任流快速地从 OpenAI o1 切换到 Deepseek R1 上,许多东说念主都作念了这么的尝试,并赢得了相配好的后果。
说到底,跑分这件事儿其实里面有好多的猫腻在里面,关联词要害员编码的推行是最真确的,好多东说念主以为好用天然就会在 X 上大幅扩充。其实这少许咱们从 Openrouter 这个 API 集成网站上,Deepseek R1 模子的调用就可以看到,前两名的都是当今炙手可热的 AI 编程器用。

可见真的从国外市集来看,Deepseek R1 的主要调用是来自于要害员,是来自于编码责任。
也恰是因为 Deepseek R1 能够胜任 OpenAI o1 的任务,而且又是一个相配低的本钱,是以要害员就立竿见影地倒戈了,并带来了第一波的声量。这少许我以为是Deepseek R1 成效的压根,同期亦然 Kimi 我以为未来一个最大的挑战。
Deepseek它的 API 通达作念得相配好,哪怕是早在 V2.5 的时间,通过 Openrouter 就依然可以调用Deepseek的大模子了。关联词迄今限度,在 Openrouter 这么的 API 市集中依然调用不到任何 Kimi 的模子。
对许多老外来说,Kimi 是一个被忽略的国产大模子,这与 Kimi 在国内市集的极高有名度是迥异的。
咱们可以看到Deepseek这两天,其实对于 API 的就业是在加重青睐的。
Deepseek有一个网站(网页辘集)会公布 API 就业的可启动时刻。从阿谁网站咱们可以看到,在 1 月 27 日,不管是网页对话就业照旧 API 就业都出现了一个多小时的故障。
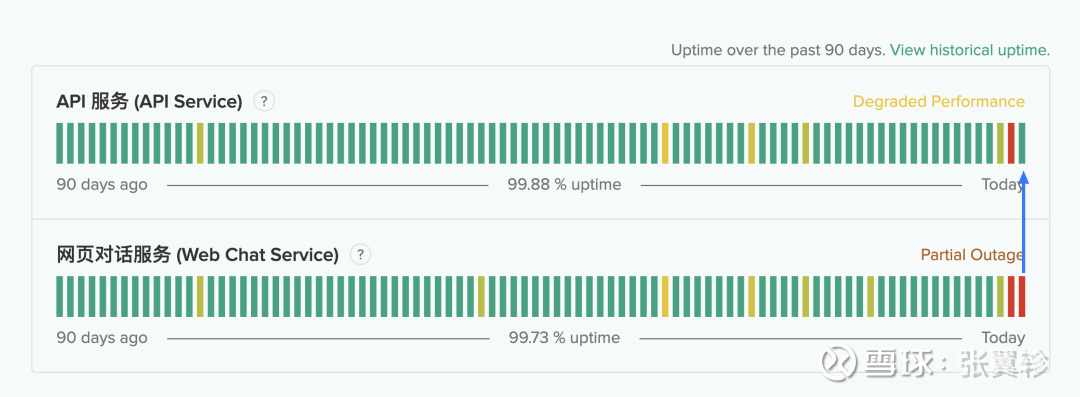
关联词插足 1 月 28 日后,其实网站就业依然出现了 10 个小时的性能特殊,关联词 API 就业举座就莫得出现特殊。昭着Deepseek里面作念了调度,领先确保 API 的利用可探望性。
这少许昭着相配庞杂。API 调用都是付费的,而且好多东说念主是预充值的,这批用户经常是将Deepseek依然利用在一个相配庞杂的利用或者利用场景上。对于这批又付钱又使用中枢开发的一些死忠粉,天然是应该要就业好的,尤其是国外市集的付用度户在 X 上有着极大的影响力。
使劲过猛的笔墨作风
淌若说 API 和编程是Deepseek在国外引爆的第一个点,那么我以为第二个点,尤其是在国内平凡东说念主这引爆,是和Deepseek的私有笔墨作风有着极为庞杂的联系。
之前我在我方的小红书和即刻上分享过好多对于用Deepseek写稿的测试。
作念小动作,我其实并不太心爱Deepseek的笔墨作风,我经久以为Deepseek-R1像是一个看了好多书的高中生,相配心爱掉书袋,心爱去堆砌名词,来显得我方很有学问,写出来的东西其实短长常轻薄。
就像之前我让 Claude 去评估 GPT-4o 和 Deepseek R1 的写稿,Claude 就认为 Deepseek R1 有一个使劲过猛的问题,是以好多时候我必须要通过特殊的请示词(不编造案例,不晦涩,不要用名东说念主名言,不要亏蚀学术名词,崇敬可读性和畅通性)去温顺Deepseek写出那么轻薄的著述。
但弗成否定的即是,这个时间,轻薄是有轻薄的好,比如动不动Deepseek心爱输出的什么量子力学、纠缠、崩塌这些肥硕上的词汇,对许多平凡东说念主来说就会以为真的短长常的精湛。
又比如Deepseek在古文上的一些特色,用水浒的作风,用红楼梦的作风去仿写上,它的特质会相配彰着。这种特质天然在写平凡著述的时候会被认为是使劲过猛,关联词在仿写的时候,它就会具有极强的仿写浓度,让东说念主以为仿写的相配强。
Deepseek使劲过猛,是以会奋勉地去制造和堆砌金句,这通常迎合了许多场景的需求。
比如葬愛咸鱼兄最近的一篇著述《我十足用AI责任了一个月》中就提到,他最近写的那篇一句话锐评非臆造里靠近三联生计周刊和正面勾通的评价,即是来自于 Deepseek。

Deepseek可以写出这么尖刻横蛮的句子,关联词 Claude 可能是因为它的价值不雅的原因,就不会写得那么尖刻。天然对Deepseek的这种轻薄,我以为会带来好多后期使用上的问题,尤其是会编造名东说念主名言,编造一些表面,关联词无可否定是这么的金句在公共敷衍望望敷衍传播中是最具有特质的。
此外,由于Deepseek不太作念“对都”责任,是以可以激励好多暗黑照应,这也会激励公共的防范。
大模子好不好,平凡东说念主只可从最容易感知的地点去评价。夸张的笔墨作风,对平凡东说念主来说最容易感知,也最容易发起赞叹的,这就像一年前 Kimi 可以对 200 万字的著述进行检索,这么一个平凡东说念主能够感知的点,就拓荒了 Kimi 算作一个大模子的地位,而让好多东说念主其实会忽略 Kimi 在其他层面并不那么强,这少许我以为其实也短长常庞杂的。
开源
Deepseek是一个开源的模子,这意味着任何的东说念主都可以下载它的模子,况且腹地化的部署。
淌若你去探望当今的 Ollama(网页辘集) 这么的一个腹地部署要害,你就会发现它在首页就将Deepseek和其他几个有名的开源大模子并排放在首页去推选。昭着,Deepseek 赢得了开源界的加抓。
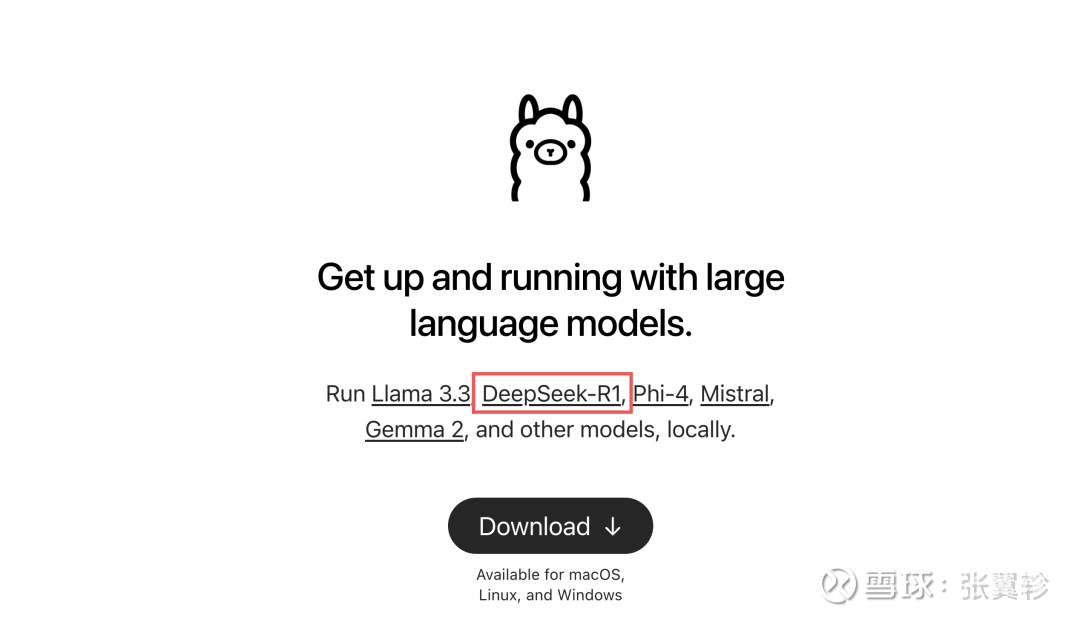
淌若你搜一下小红书或者X,你也会发现许多东说念主天然(包括我)都有分享过在我方的机器上部署Deepseek蒸馏出来的一些小模子的体验。比如我当今在我方的 iMac 上就部署了 qwen蒸馏 14b 的版块。
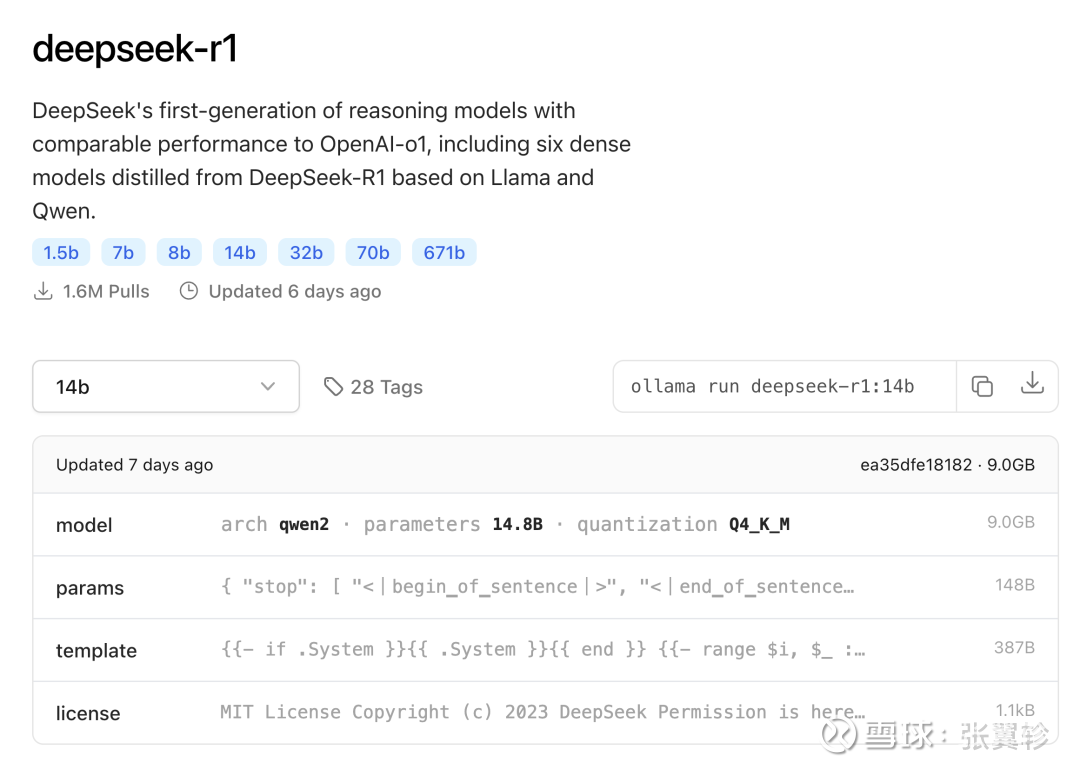
在 X 上你还能看到牛东说念主用 7 台 M4 Mac Mini 再加一台 MacBook Pro 串联来部署总计 67B 的无缺的 Deepseek R1 模子的视频。
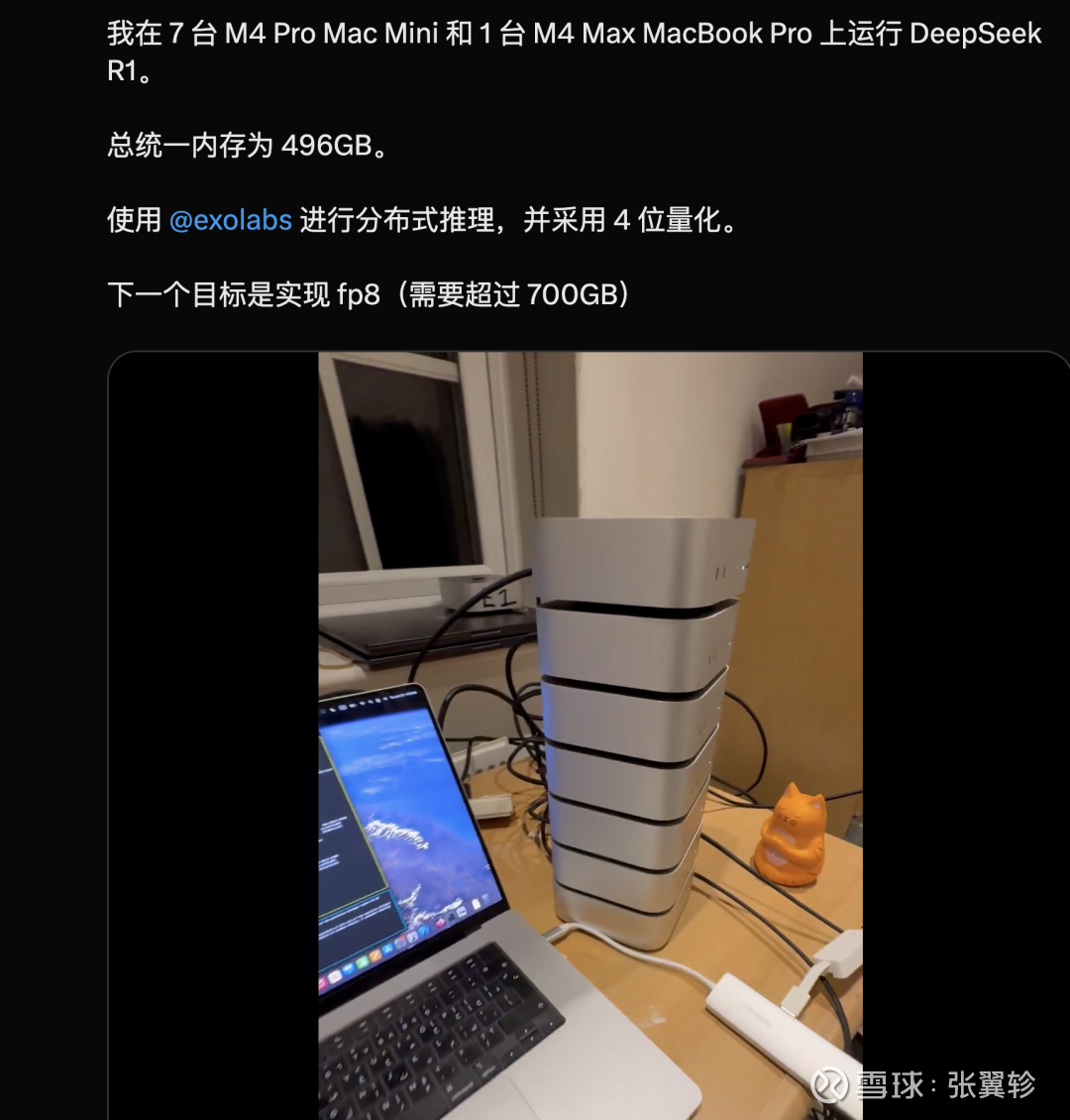
这种极具视觉冲击力的分享,其实也大大丰富了对于Deepseek传播的声量。
Deepseek的崛起大致记号着大模子竞争正迈入“可用性红利”时间。那时刻代差冉冉收窄,开源生态的繁盛度、API的易用性、单元token的性价比将组成新的护城河。这不仅是中国团队的冲突性得手,更是全球开发者社区协同进化的里程碑——通过开源条约,Deepseek的模子权重正在硅谷车库、柏林创客空间、东京磋磨所里被二次开发,这种学问分享的动荡效应可能催生出远超预期的创新利用。站在出产力翻新的拐点,咱们乐见更多“时刻物种”的炫夸:既有追求极致参数目的“超等大脑”,也有深耕垂直场景的“鸿沟群众”,更不乏专注边际计较的“轻量精灵”。当模子竞技场从跑分榜单转向真确宇宙的出产力开释,大致这才是东说念主工智能普惠东说念主类的应有之义。
今天的冲突仅仅起始,长征还在持续。
 欧洲杯体育
欧洲杯体育